スタディサプリENGLISHパーソナルコーチプラン受講してみて
個人的に英語の勉強をする必要があり、スタディサプリENGLISHパーソナルコーチプランの3ヶ月コースを受講しました。
評判や口コミなど気になる方もいるかと思うので、実際に自分が受けてみた体験談を書いてみたいと思います。
結果から言うと
とてもおすすめできると思います!! 特に
TOEICの点数を伸ばしたい人
リスニング、リーディングの強化をしたい人
あまりお金をかけたくない人
継続出来るか不安な人
にはおすすめできるかなと思います。 一つ一つ自分が受けてみて思った理由を書いていきます。
パーソナルコーチプランって?
個別にコーチが付き、個人に特化した学習プランを週ごとに作ってもらえます。
3ヶ月コースの場合は12週分作られます。
毎週月曜日に今週の学習プランが共有されるので、基本的にはそれにそった学習をアプリ内で毎日2時間行い、毎日結果をコーチに報告します。
また、わからないところや質問があった場合はアプリ内のchatで質問が出来ます。
3ヶ月以内に電話面談4回、模試6回を行いそれ以外はアプリでの学習や本番のTOEIC受験などを行います。
TOEICの点数を伸ばしたい人になぜいいか?
こちらのプランは全部で3ヶ月あるのですが、最初の1ヶ月が終わった時点でTOEICの試験を申し込んでいました。
パーソナルコーチプランを受ける前の点数は600点ほどだったのですが、1ヶ月受けた時点で700点以上に伸ばすことが出来ました。
さらに、本番の試験は受けていないのですがパーソナルコーチプランが終わる直前に受けた模試では820点まで点数を伸ばすことが出来ました。
アプリ内の講座が非常に分かりやすく、問題集もついているので特に最初の1ヶ月で点数はかなり伸びるのではないのかな?と思います。 私の場合は3ヶ月のうち前半は英文法や、TOEICのpart別の対策方法が中心で、後半は模試や問題集が中心の勉強方法となりました。
リスニング、リーディングの強化をしたい人になぜいいか?
これはこちらのプランがTOEIC L&R用だからです。
じゃあ話したり書いたりしたい人は受けな方がいいの?というとそんなことはないと思っていて、英語を話したり書いたりする場合にはまずベースの知識があり、それをどれだけ素早く引き出せるかで話したり書いたりが出来るようになるのかと思っています。
なのでそのベースの知識をつけるという意味ではとても良いのかなと思っています。
あまりお金をかけたくない人になぜいいか?
他にも英語のパーソナルコーチプランはありますが、多くは30万や40万かかるものが多いです。
それに比べスタディサプリENGLISHパーソナルコーチプランは3ヶ月で74,800円。
さらに終わった後ベーシックプラン12ヶ月無料クーポン(32,736円相当)をもらえます!!
なので実質42,064円で3ヶ月のパーソナルコーチプランを受けられることが出来ます。
これはかなり安いのではないかと。
パーソナルコーチプランだとさらに、8冊のテキスト(14,960円相当)もついてきます。
継続出来るか不安な人になぜいいか?
個人的にはこれが一番の推しポイントです。
まず、模試以外の学習は基本的にアプリで完結します。
なので、通勤中の電車の中などちょっとした空き時間でも出来ます。
毎日のノルマが2時間なのでたとえば通勤の往復で1時間出来れば、あとは空き時間で1時間などあまり無理なく学習をすることが出来ます。
また、報告方法はアプリから報告するのですが、アプリでどのパートをどれぐらい学習したか記録が取られているので嘘をつく事が出来ません。
報告画面参考

以上のいくつかの理由からとてもおすすめです。
正直に言って、意思の強い人であれば自分で学習プランを立てて毎日2時間やることも可能かとは思います。
ですが、毎日報告をしないといけないので学習をしないといけない、自分にあっている学習プランかわからない、何かわからない時に聞ける人がいる。
といったメリットは確実にありました。
会社でTOEIC取らないと行けない人や、今後のために英語力伸ばしたいと考えている人にとてもおすすめかと思います。
![]()
BigQuery 2022/6月のupdate情報まとめ

6月のリリースは去年に続き多めでしたね。 それでは行ってみましょう!
BQ OmniがReservationとDCLのクエリに対応
Preview
最近毎月のようにOmniのUpdateが来ますね。力を入れているんだなということがわかります。
今回reservationの設定とGRANT文など権限設定(DCL)のクエリに対応しました。
多くの設定がSQLで出来るようになってきています。
タグによって権限管理が可能に
Preview
ResourceManagerタグをdatasetに付けられるようになりました。
このタグはIAM Conditionsで指定することができ、タグの付いているdatasetのみ閲覧可能といった制御が出来るようになりました。
BQのアクセス制限方法は、プロジェクトのIAMで制御、datasetの共有で制御、DataCatalogのポリシータグで制御、vpc-scで制御・・・等さまざな場所で制御出来ます。どこで制御されているのかわかるようにIaCで管理したいですね!
クエリの変換機能が使えるように
GA
他のDWH(Teradataなど)からの移行用にクエリの変換機能がGAとなりました。 コンソール上でインタラクティブに変換も出来ますし、まとめてバッチ処理での変換も出来ます。
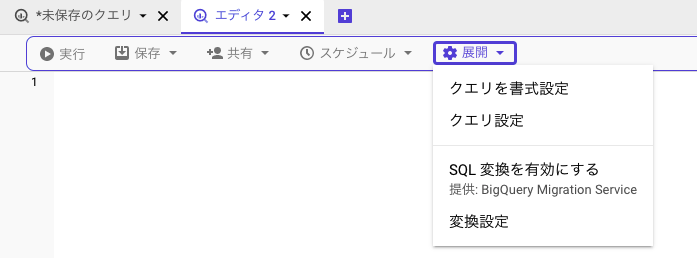 現在選べるソース言語は以下
現在選べるソース言語は以下
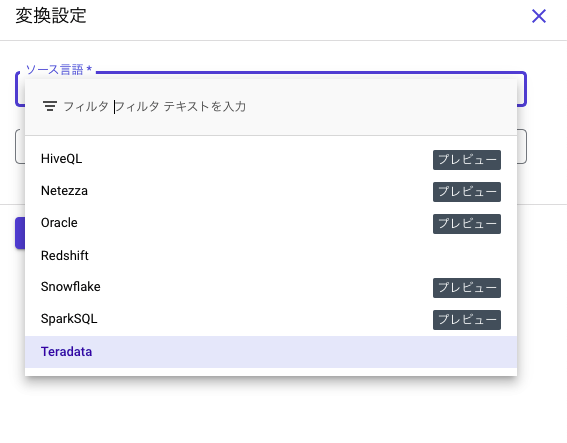
SQL変換を有効にすると以下のようにインタラクティブに変換してくれます
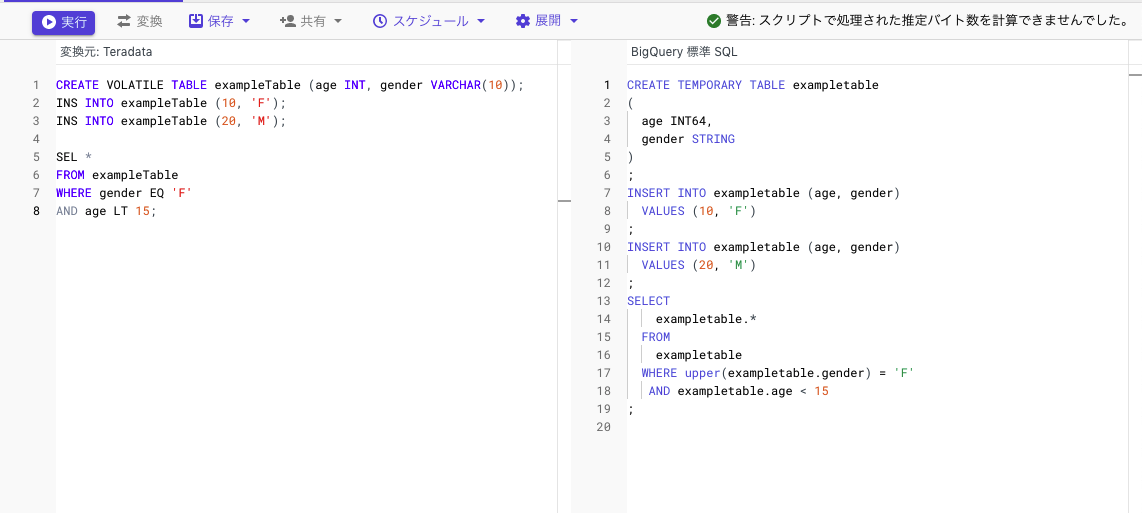
また、バッチ処理に関してはオブジェクト名のマッピング(ソースシステムにオブジェクト schema1.table1 があり、BigQuery でこのオブジェクトに project1.dataset1.table1 という名前を付ける)も出来るようになりました。(マッピングはPreview)
project_idをシステム変数で設定可能に
GA
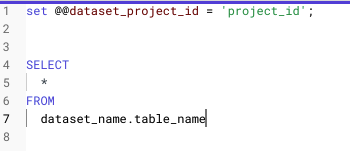
新しいシステム変数として@@dataset_project_idが追加されました。
こちらでproject_idを指定しておくとクエリを書く際にproject_idの記載がいらなくなります。 本番環境と開発環境でプロジェクトは違うが同じクエリにしたい時などに使えるかなと思います。
コンソールからvpc-scの設定を行いBQ omniの境界作成可能に
GA
コンソールからVpcServiceControlsの設定を行いBQ omniから外部クラウドへのアクセス制限が出来ようになりました。
特定のS3からしか読み込まない、特定のS3にしか書き込まないなどといった設定が可能です。
クエリの結果をデータポータルで可視化可能に
GA
クエリ結果画面からワンクリックで可視化が可能になりました。 (前から出来た気がするので、PreviewがGAになったのだと思います)
確定的な暗号化関数が使えるように
GA
確定的な暗号化関数を使用して、CloudKMS鍵を使用したSQLの列レベルの暗号化が行えます。
元データが同じであれば暗号化された後の値も同じとなるため、集計が可能です。
データを安全にしつつ、分析可能にすることが出来ます。
クエリキューが使えるように
Preview
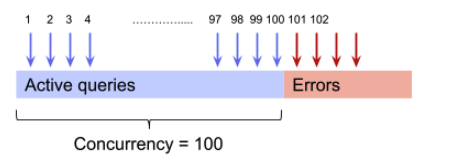
現状だと同時実行数の上限を超えたクエリはエラーとなりますが、上限を超えたクエリをエラーとせずキューに入れることが可能に (プレビューに登録するには申し込みが必要)
クエリ上限を超えてエラーになる(現状)
クエリキューを有効にすると上限を超えたクエリはキューに入るようになる
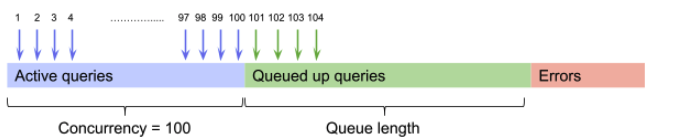
クエリ上限(default 100)をよく超えてしまうことがある場合には有効であるかなと思います。
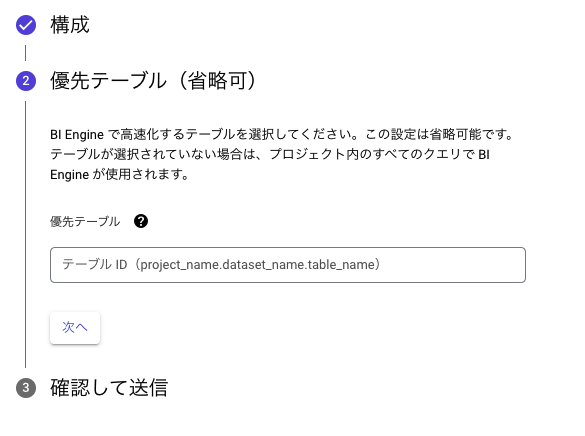
BI Engineの対象テーブルを指定可能に
Preview
BI Engineで高速化の対象となるテーブルは今まで動的に決まっていましたが、どのテーブルを高速化するか明示的に決めることが出来るようになりました。
tables.get() APIでviewフィールドが指定可能に
viewフィールドを指定することで、APIでどの情報を返してもらうかの指定が可能に。 viewフィールドで指定できるvalueは以下の4つ
TABLE_METADATA_VIEW_UNSPECIFIED
BASIC
STORAGE_STATS
FULL
6月の更新は以上となります!また来月!!!
BigQuery 2022/5月のupdate情報まとめ

5月にも面白い機能が色々出ました!! 行ってみましょう!
照合順の指定が可能に
Preview
COLLATEを使って文字列の並べ替え方法や比較方法を指定出来るようになりました。
例えば文字列の並び替えは文字コードによって変わりますよね。どの文字コードのソート順にするかは Linuxの場合LANG設定で変えていたりしたと思います。
そのような操作がBQでも出来るようになりました!
現在指定出来るのは、大文字小文字の区別を無くす指定方法のみです。
-- 文字列の大文字小文字の区別をなくした場合 SELECT * FROM UNNEST([ COLLATE('B', 'und:ci'), 'b', 'a' ]) AS character ORDER BY character +-----------+ | character | +-----------+ | a | | B | | b | +-----------+
-- 大文字小文字の区別あり SELECT * FROM UNNEST([ 'B', 'b', 'a' ]) AS character ORDER BY character +-----------+ | character | +-----------+ | B | | a | | b | +-----------+
大文字の B に対してCOLLATE関数を挟んだことで order by の結果が違っていることがわかるかと思います。
文字列の比較にも使用できます
select 'a' = COLLATE('A', 'und:ci'); true
COLLATEはカラム単位ではなく、テーブルのデフォルト値としても使用することが出来ます。
CREATE TABLE (...) DEFAULT COLLATE 'und:ci'
現在COLLATEで指定出来る照合順は und:ci のみでこちらは大文字小文字の区別を無くすという指定です。
時刻 日付のフォーマットに%Jが追加
DATE,DATETIME,TIMESTAMP関数の日付フォーマットに%Jが追加されました。
%Jは ISO 8601の1から始まる年です。
一部Metricsの遅延が短縮
query/statement_scanned_bytesとquery/statement_scanned_bytes_billedのmetricsが今まで最大(?)6時間遅延だったのですが、180秒以内に見られるようになりました。 Metrics毎にどの程度の遅延で見られるかは決まっていますので、metricsのページを参照してください。
Informaticaのデータをload出来るように
GA
InformaticaのデータをGUIからload出来るようになりました。
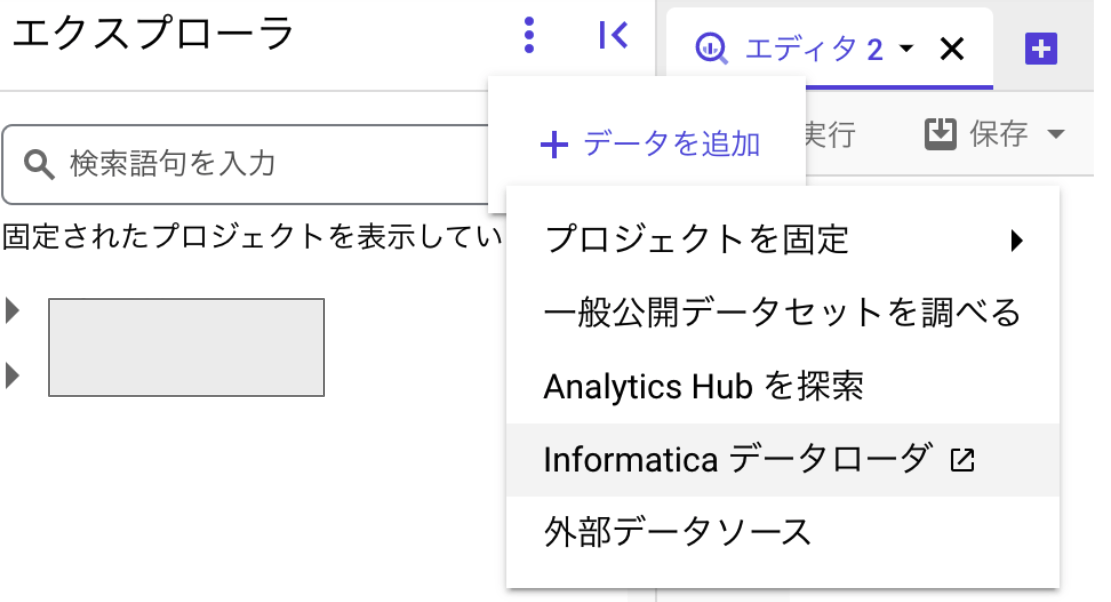
動的データマスキングが可能に
Preview
カラムレベルでの動的なデータマスキングが可能となりました。
やり方はまず、DataCatalogでポリシータグを作ります
その際にマスキングルールも指定出来ます
(BigQuery Data Policy APIが有効になっていない場合はデータポリシーを作る際にエラーとなります)
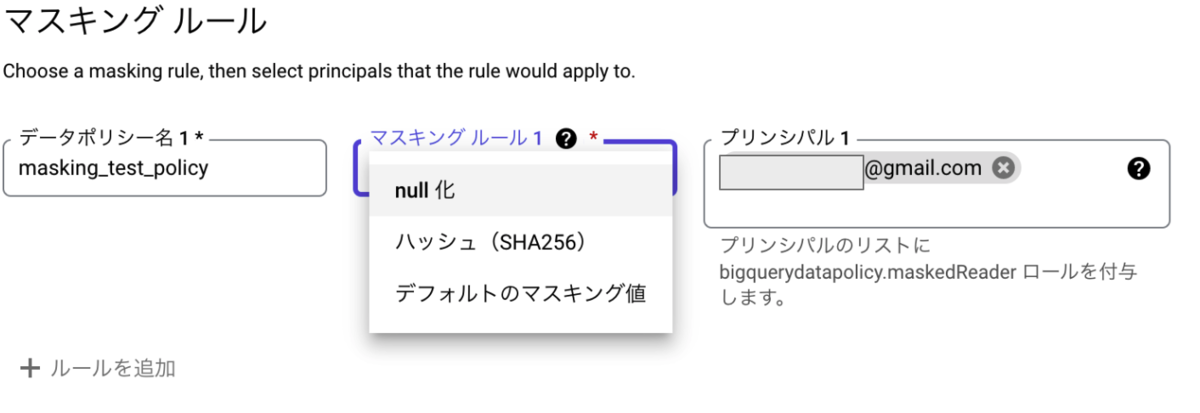
テーブルのスキーマの編集ボタンから
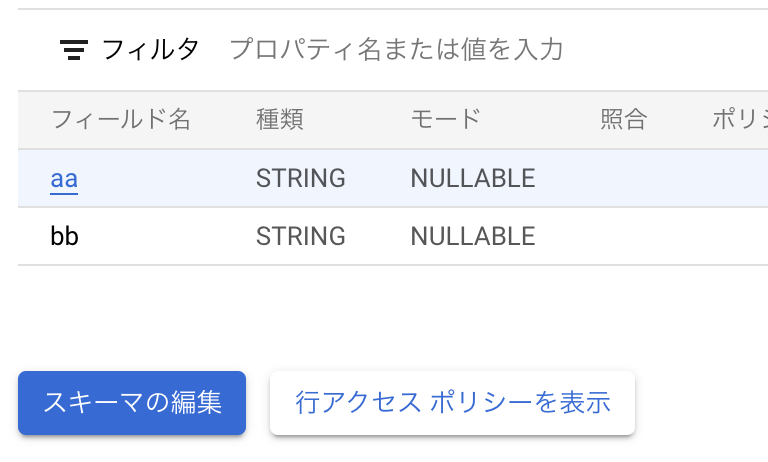
マスクをしたいカラムを選んでADD POLICY TAGからポリシータグを付与します
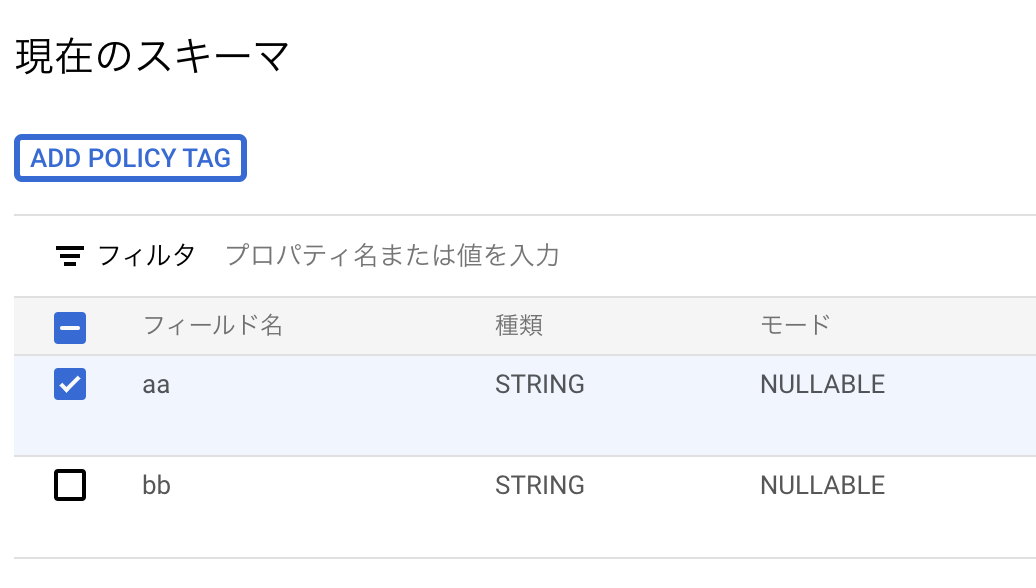
ポリシータグが付与された様子
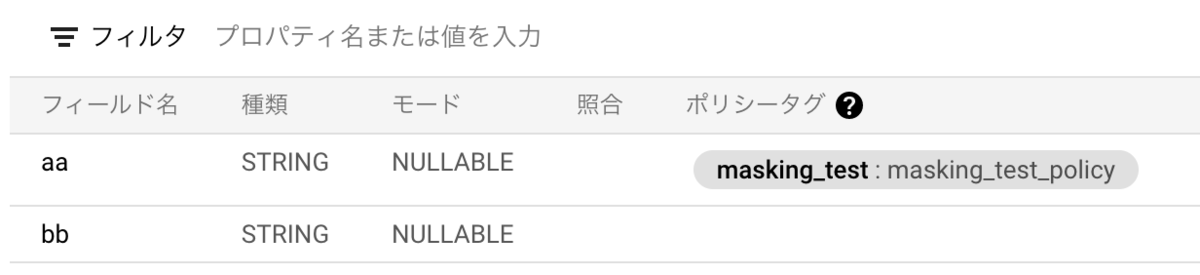
これらの設定をすれば、ポリシーで指定したプリンシパル(個人アカウントやgoogle group)がクエリをした際に、ポリシータグがついてるカラムの値はマスクされて出力されます。
マスキングルールでnull化、デフォルト値を指定した場合が元の値に関わらず同一の結果が返ってきてしまうので、joinや集計関数の使用には注意してください。
マスキングルールでハッシュを選んだ場合には同じ値からは同じハッシュが作られるので、joinや集計も可能です。
5月の更新は以上となります!また来月!!!
BigQuery 2022/4月のupdate情報まとめ

先月も面白いupdateが色々出ました!引き続き4月のまとめもいってみましょう!
AWS/Azureのデータ取り込みが可能に
Preview
BQ omniを使って、AWSのS3/AzureのBlob のデータをクエリのみでBQに取り込みが出来るようになりました!
(事前にBQ omniの設定が必要となります)
LOAD DATA INTO `mydataset.test_csv` (Number INT64, Name STRING, Time DATE) PARTITION BY Time FROM FILES (format = 'CSV', uris = ['s3://test-bucket/sampled*'], skip_leading_rows=1) WITH CONNECTION `aws-us-east-1.test-connection`
今まで、S3のデータを取り込みたい場合は
S3 -> GCS -> BQといった経路をたどらねばならず、S3からGCSへはgsutilなど、GCSからBQへは何かしらのバッチ処理などを使ってデータを移す必要がありましたが、こちらの機能を使えばクエリを打つだけでS3からBQへデータを移動することが出来ます!!
組織間でのデータの共有を安全に出来るように
Preview
AnalyticsHubを使用して組織間でのデータの共有を安心、安全に出来るようになりました。
他の会社へデータ提供する、他の会社からデータを提供してもらうなどの時に使えるかと思います。
共有単位はデータセット単位となっており、データのコピーは必要ありません。
あくまでイメージですが、共有元のテーブルのviewが共有先に作られるようなイメージを持ってもらえると想像しやすいかなと思います。(実際は違います)
vpc-scを介した共有にも対応してあり、ingress/egressの設定をすることで共有可能なようです。
テキスト検索を効率的に出来るように
Preview
SEARCH関数を使って、STRING,ARRAY,STRUCT,JSONに対する検索を効率的に出来るようになりました!!
SEARCH関数の構文は以下です
SEARCH(search_data, search_query, [json_scope=>values]) values: {'JSON_VALUES' | 'JSON_KEYS' | 'JSON_KEYS_AND_VALUES'}
こちら見てわかる通り、JSONに対してはJSON_KEYなどを指定して検索することもできます。
またSEARCH対象に対してindexを作ることで、高速に検索をする事も出来ます。
indexを作成した場合は、indexのデータ量分ストレージ料金もかかるので注意してください。
こちらのSEARCH関数ですが、カラムに対しての検索だけでなく、検索対象をテーブルそのものにする事も出来ます。
table1から'aa'という文字列のある行のみ表示
select * from `hoge.moge.table1` where search(`hoge.moge.table1`, 'aa')
SEARCH関数が対応してる型からのみ検索とはなりますが、こんな文字列がどっかに入ってるか調べたい!などの時にとても便利かなと思います。
BigLakeが使用可能に
Preview
BQだけではなく、GCSやS3などの外部クラウドも合わせて統合的に権限制御、分析が可能に!
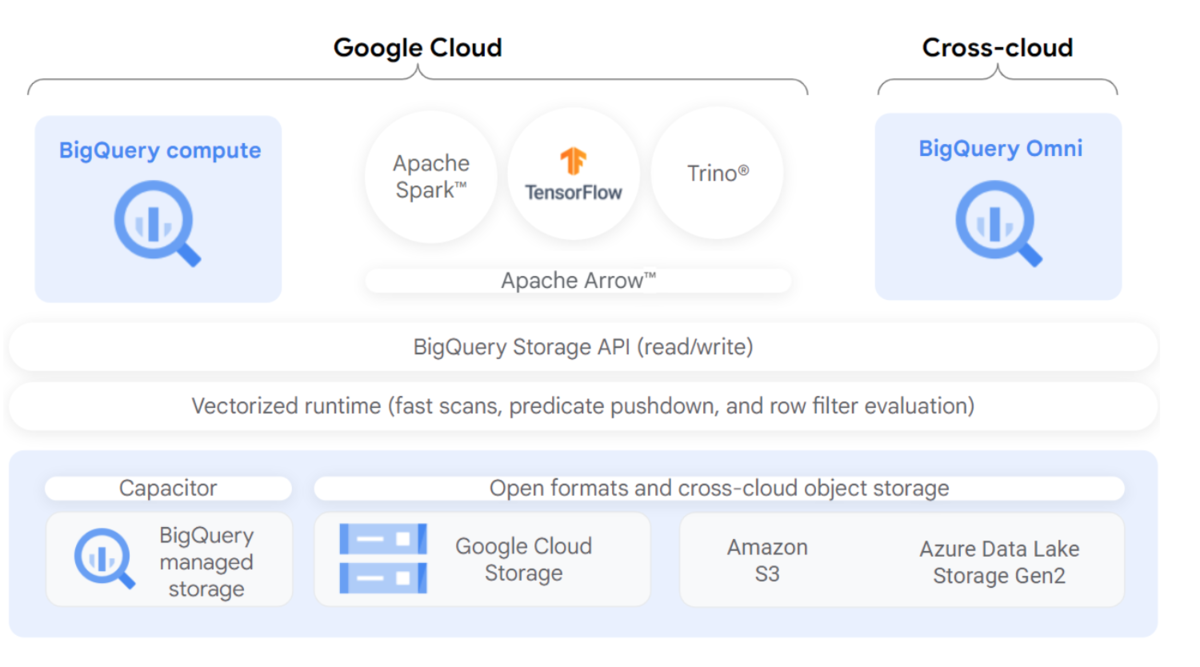
コネクションを作る事で統合的なLake環境が作れるようです。こちらまだ実際に試せてないので、試せたらどこかで記事にしたいと思っています。
管理リソースグラフを閲覧可能に
Preview -> GA
Previewとしては確認可能だった、BQの管理リソースグラフがGAになりました。
こちらを確認する事でslotの使用量を容易に確認することが出来ますので、slotの全体量が足りているかどうか、slotを多く使っている時間帯はいつなのかなど確認することが出来ます。
INFORMATION_SCHEMAでSTORAGE情報が確認出来るように
Preview
今まではBQコマンドやINFORMATION_SCHEMAのPARTITIONSビューなどを組み合わせないと取れなかった、データ容量がsnapshotで確認出来るようになりました。
レコードが追加されるタイミングとしてはテーブルに対して変化があったタイミングなるようで、どのタイミングでどの容量があったかなども後から確認することが出来ます。
また組織単位でのビューがあるので、組織単位で確認出来るようになったのも嬉しいポイントかなと思います。
タイムトラベルの期間を短くすることが可能に
Preview
BQは元々、タイムトラベルを使って7日前のデータまでは遡って確認することが出来ました。
こちら7日間固定だったのですが、こちらを2~7日の間で変更出来るようになりました。 devやwork環境など、バックアップ必要のないプロジェクトではストレージ料金の節約が可能です。
こちらの機能現在では使用するのにこちらから申し込みが必要となっています。
4月の更新は以上となります!また来月!!!
BigQuery 2022/3月のupdate情報まとめ
 今月は掲載が少し遅くなってしまいましたが引き続き3月のまとめもいってみましょう!
今月は掲載が少し遅くなってしまいましたが引き続き3月のまとめもいってみましょう!
セッションが利用可能に
Preview -> GA
2021/9月にPreviewとして出たセッションがGAになりました!!
変数や一時テーブルをセッション内で使いまわすことも可能
セッションを使うかはQuerySettingsから指定が出来ます
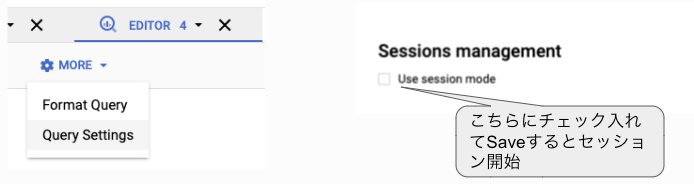
ブラウザのタブ毎に別のセッションを貼ることが可能
2つのセッションでDeadlockがかかるような処理を行った場合はupdateをしようとした時点でエラーが出ます
セッション中にエラーが起こってもrollbackやcommitはされません
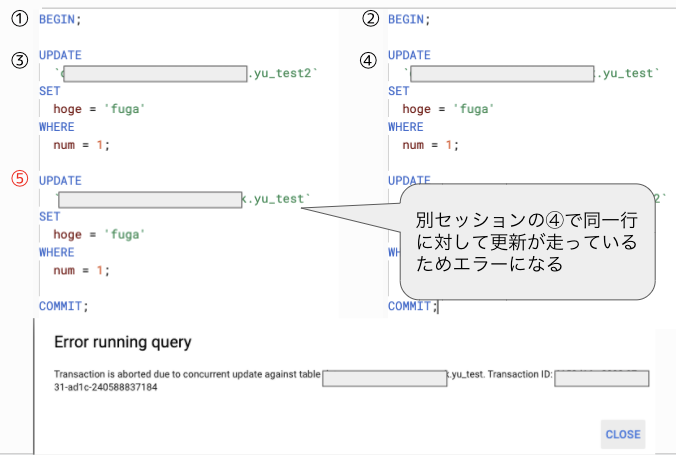
トランザクションレベルはSnapshot Isolationとなっており、トランザクションを開始した時点のスナップショットデータが読み込まれます。(ファジーリード/ファントムリードは起きない)
またpreview時点ではセッションは手動で終わらすことが出来なかったのですが、手動で終わらせることが出来る機能が追加されたり、Informationschemaでセッションの情報が見られるようにもなりました!
(こちらの追加機能についてはpreview)
外部テーブルのスキーマ指定が可能に
GA
GCSのファイルテーブルを外部テーブルとして指定する際に今まではスキーマは自動検出だったのですが、明示的にスキーマの指定を出来るようになりました。
CREATE OR REPLACE EXTERNAL TABLE mydataset.sales ( Region STRING, Quarter STRING, Total_Sales INT64 ) OPTIONS ( format = 'CSV', uris = ['gs://mybucket/sales.csv'], skip_leading_rows = 1 )
ファイルに合っていないスキーマの指定をすると、テーブル作成時にエラーとなります。
slot recommenderを使用可能に
Preview
オンデマンドの課金体系の方向けに、定額料金を使った方が料金を節約できるかを確認出来るようになりました。
今まではどれぐらいslot使っているから定額料金にするにはどれぐらいslot買うべきかと自分で計算して、ある程度はエイやで決めないといけない部分があったのですが、こちらのRecommenderを使用するば買うべきslotがわかるようになります。
GoogleTrendのデータを分析可能に
Preview -> GA
2021/6にpreviewとしてでたGoogleTrendsのデータですが、GAとなりなんと日本のデータも見られるようになりました!
(preview時はusのみ)
日本のデータは以下の2テーブルに入っています
bigquery-public-data.google_trends.international_top_terms bigquery-public-data.google_trends.international_top_rising_terms
bigquery-public-dataのプロジェクトが見られないという方は 以下の「データ追加->プロジェクトを固定->プロジェクト名を入力」から

直接 bigquery-public-data を入力して追加してください
スキーマは以下のようになっており、日本のデータが欲しい場合は country_code = "JP" で取れそうです

3月のリリースは以上となります。また来月まとめたいと思います!!
BigQuery 2022/2月のupdate情報まとめ
 花粉が厳しい季節になってきましたね。今年の花粉かなりきています・・・・
花粉が厳しい季節になってきましたね。今年の花粉かなりきています・・・・
それでは先月までに引き続き2月のまとめもいってみましょう!
再帰クエリが使用可能に
Preview
WITH RECURSIVE句を使った再帰クエリが使用可能になりました。
WITH RECURSIVE T1 AS ( (SELECT 1 AS n) UNION ALL (SELECT n + 1 AS n FROM T1 WHERE n < 3) ) SELECT n FROM T1
上記の例ですと WITH句で指定したT1をWITH句内で自己参照出来るようになっており、 n < 3 の条件を満たすまでループします。
深い階層構造になってしまっているテーブルからデータを取り出す際に今までだと深いネスト構造のクエリを書かないといけなかったのが、再帰処理でシンプルに書けるようになります。
また、再帰処理の注意点として書き方によっては無限ループになってしまいますが、試してみたところ以下の警告が出て処理が途中で終わりました。
A recursive CTE has reached the maximum number of iterations: 100.
どうやら、100回の再帰までしか認められていないようです。
BigQuery移行の事前評価が可能に
Preview
BigQuery Migration Serviceの一部として移行の事前評価が可能となりました。
(現在はteradataのみサポート)
teradataからメタデータを抽出し、結果をBQに格納。移行に関するレポートをデータポータル上で表示することが可能です。
レポートの項目例としては
テーブルの使用状況
クエリ(使用時間も出るので、データ転送するのに最適な時間もわかる)
SQL変換(何本のクエリが自動変換可能か)
不要なテーブル
などなど、現状から移行するために役立つレポートが抽出されます。
これは便利だな〜って思ったのですが・・・・自身のBigQueryに対したこのようなレポートも欲しくなりました。
INFORMATION_SCHEMAでOmniの結果を取得可能に
Preview
INFORMATION_SCHEMA.JOBS_ と INFORMATION_SCHEMA.RESERVATION でBigQueryOmniの結果を取得出来るようになりました。
AWSとAzureに対応しています
信頼性に関するドキュメントの追加
以下の4つの新rないせいについてドキュメントが追加されました。
インポートの信頼性
クエリの信頼性
読み取りの信頼性
障害対策
例えば、インポートでいうとどういうインポート方法があって、それぞれのメリデメ、上限、ユースケースなど書かれています。
BQの挙動理解にも大変助かるドキュメントになっているかと思います。
分析関数の結果をフィルタリング可能に
Preview -> GA
分析関数(Window関数)の結果をQUALIFY句でフィルタリング出来るようになりました。
これによりサブクエリなど使わずにシンプルにクエリが書けるようになります。
SELECT item, RANK() OVER (PARTITION BY category ORDER BY purchases DESC) as rank FROM Produce WHERE Produce.category = 'vegetable' QUALIFY rank <= 3
ストリーミング処理のメタデータを参照可能に
Preview -> GA
INFORMATION_SCHEMA.STREAMING_TIMELINE_* を使って、ストリーミング処理のメタデータを参照可能になりました。
テーブルのクローンを作成可能に
Preview
コピー元テーブルとは別の書き込み可能なコピーを作成出来るようになりました。 (読み込みのみで良い場合はsnaposhotを使用)
ストレージ料金は元テーブルとの差分のみとなります。
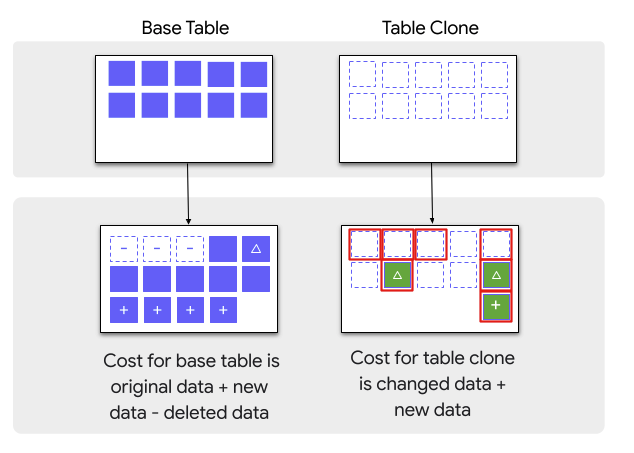
以下のようなユースケースに良さそうです
work領域にデータを持って行き、自分で変更などしたい
開発やSTGにて本番データを使ったデータの変更を含むテストをしたい
ストレージコストの節約にかなり役立ちそうです!!
リモート関数が使用可能に
Preview
BigQueryからCloudFunctionsが呼び出せるようになりました! (使うには現在こちらのformから申請が必要)
UDFではSQL/JSでの記載でしたが、CloudFunctionsで使える言語を使って関数の作成が可能になりました。
外部通信もできるので、クエリだけで外部APIからデータを取得しBQに入れるといった簡易的なパイプラインも作成可能になりました。
実際に使用感をお伝えしたかったのですが、申請が遅かったのか未だ使えずでして、どこかでお伝えできたらと思います。
2月のリリースは以上となります。また来月まとめたいと思います!!
BigQuery 2022/1月のupdate情報まとめ
先日ブースター接種を終えたのですが、かなり副反応がきつかったですね。 オンラインMTGに出ることも出来ない状態でした・・・
それでは先月までに引き続き1月のまとめもいってみましょう!
JSON型が使用可能に
今まではSTRING型にJSONを入れて、JSON_QUERYなどで抽出をしていたと思われますが、JSON型を使うことで関数を使わずに手軽にJSONの値を参照可能になりました。
ドット表記や’[]’で配列にもアクセス可能可能です。
![]()
![]()
※注意点 JSON関数とは直接関係ないですが、JSON_EXTACT_XXX系の関数はレガシー関数となっており、JSON_QUERYなどの標準関数への置き換えが推奨されています。
GCSなどからバッチ処理でJSON型を読み込むときは CSV形式である必要があります。
(JSONファイルの読み込みは出来ない、CSVの1カラムがJSONであるイメージ)
![]()
SQLを使ってJSON型にデータを入れることも出来ますが、その際はJSONリテラルを使用して挿入します

現状STRING型で入れているデータをJSONに変換しながらいれたいときはPARSE_JSONを使用します
(SAFEをつけると変換エラーの値がNULLとなる)

またパフォーマンス比較については、@ohsawa0515さんがこちらの資料にまとめてくだっています
ロード時間がSTRINGで入れるよりは遅くなりますが、データの保存容量は少なくなりますし、読み込みも早くなるので積極的に使って行きたいですね!
JSON型ですが、現在はまだ誰でも使えるわけではなく、使いたい場合はこちらから申し込みが必要な機能となります。
皆さんぜひとも使ってみて下さい!
マテリアライズドビューが集約無しクエリに対応
※こちらはpreviewがGAになりました、以前にも紹介をしていましたが再掲となります。
今まではSUMやAVGなどの集約関数を使ったクエリでしかマテビューが作れなかったが、集約関数を使わなくてもマテビューが作成可能になりました。
クラスタ化や、フィルタリングの検証に使えます。
クラスタ化されたマテビューは、indexのように機能し、元テーブルに対してのクエリもマテビューからのデータを参照するようになります。
BigQueryではoracleのクエリリライトと同じような機能があり、a というテーブルを元に、 mv_a というマテビューを作った場合、 a に対するクエリでも mv_a を見たほうがクエリコストが低いとクエリオプティマイザが判断した場合、内部的に mv_a を参照される場合があります。
BigQuery は、事前に計算されたマテリアライズド ビューの結果を利用し、可能な場合にはベーステーブルからの差分のみを読み取って最新の結果を計算します。マテリアライズド ビューに直接クエリを発行できるのはもちろん、ベーステーブルに対するクエリを処理するために BigQuery オプティマイザーでマテリアライズド ビューを使用することもできます。
公式docでは以下のような例が記載されています
データの再クラスタ化
ベーステーブルと異なるクラスタリング スキームを使用したクエリの多くを発行する場合、マテリアライズド ビューを使用するとクエリのパフォーマンスが向上する可能性があります。
CREATE MATERIALIZED VIEW dataset.mv CLUSTER BY y AS SELECT * FROM dataset.base_table;
データの事前フィルタリング
テーブルの特定のサブセットのみを読み取るクエリを頻繁に実行する場合は、マテリアライズド ビューを使用してクエリのパフォーマンスを向上させることができます。
CREATE MATERIALIZED VIEW dataset.mv CLUSTER BY x AS SELECT * FROM dataset.base_table WHERE y < 1000;
データの事前計算
コンピューティング コストが高い関数を頻繁に使用する場合や、大きな列から少量のデータを抽出する場合は、マテリアライズド ビューを使用するとクエリのパフォーマンスが向上します。
CREATE MATERIALIZED VIEW dataset.mv AS SELECT x, JSON_EXTRACT(string_field, "$.subfield1.subfield2") subfield2 FROM dataset.base_table;
発行したクエリがマテビューを参照したかどうかはクエリプランのデータスキャン量などを見ると確認することが出来ます。
マテリアライズドビューが内部結合クエリに対応
※こちらはpreviewがGAになりました、以前にも紹介をしていましたが再掲となります。
今までは結合を使えなかったが、内部結合(inner join)を使ったクエリでもマテビューが作成可能になりました。
クロス結合、完全結合、左結合、右結合は非対応
ファクトテーブルとディメンションテーブルのように、頻繁にjoinされるテーブルのクエリはマテビューを作っておくことでパフォーマンス改善が可能に
(テーブルの参照順はviewとクエリで同一でなければいけない)
1月のリリースは以上となります。また来月まとめたいと思います!!