子連れキャンプに行くようになって追加で買ったもの
キャンプAdventCalendar 17日目の記事となります。
イクジニア(育児 + エンジニア)といいながら育児関連のことを全然書いてなかったので久々に・・・
今年は子連れキャンプに数回行かせてもらい、課題が見えるたびに道具を買い続けたので買ってよかったものをいくつか紹介させていただければと思っています!!
ハンモック
最初から遊び道具!?って感じですがこちら買って本当に良かったです
4歳6歳の2人の子供を連れてキャンプ行ってるのですが、キャンプ場に遊具がないとタープ貼ったりテント立てたりしている間に子供が飽きてしまうとか、しっかりと見ていられないので気づいたらいなくなっているとかがあるかなと思います。
(うちのタープは大人2人がかりでないと建てられないタープだという事情もありますが・・・)
ハンモックがあるだけで、子供は喜んで遊んでくれますしその間に大人は設営作業や料理の準備に集中出来ます。
今回買ったハンモックはこちらです
ハンモックとして使い終わった後はハンガーになるので、ランタンなどを吊るしたりも出来ます
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/227d5416.fd4f59e6.227d5417.e5691a45/?me_id=1305616&item_id=10000103&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fajia-shop%2Fcabinet%2Fitem%2Fthumwtbg%2Fthummulti.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

ゴムハンマー
ハンモックで遊んでいてもらっても、大人がペグを打っていると子供がやりたがります。
その際に自分がペグを持ちながら、子供にペグハンマーで打ってもらったところ手を強打されましたToT いや〜めっちゃ痛かった・・・
だからといって子供にやらせないのもせっかくキャンプに来ているのでもったいないと思いゴムハンマーを購入しました。
こちらでもやらかい地面であればペグが打てますし、なにより手を打たれても(そこまでは)痛くありません!!
兄弟で喧嘩にならないように2つ購入しました。 ダイソーやセリアなどの100均で購入出来ます。
黒ゴムパイプハンマー8オンスK45jp.daisonet.com
焚き火台テーブル
キャンプの醍醐味はなんと行っても焚き火だと思っています。
焚き火楽しいですよね!!
ですが、好奇心旺盛な子供は焚き火に近づき過ぎてしまい、結構危ないことが多かったので子供のガードのためにもと焚き火台テーブルを購入しました。
結果夕飯時にはみんなで焚き火を囲んでその場で焚き火を使って調理したものを食べられるし、焚き火に近づく危険性も減ったので大変よかったです。
今回購入した焚き火台テーブルは尾上製作所のものを購入しました。
焚き火台はLOGOSの the ピラミッドTAKIBI L を使っていますが、大きさ的にも丁度いい大きさでした。
ガイドロープランプ
キャンプ中に(特に夜間)子供がガイドロープにひっかかって転ぶということが何回かありました。
まあ子供は転ぶものですし、よいのですが運悪く転んだ先にペグなどがあったばあいは大怪我に繋がりかねません。
とくにうちのテントの場合は出口のところにガイドロープがあるタイプなので、夜のトイレなどで大人も転びそうになりました。
そのような危険性を回避するためにガイドロープにつけられるランプを購入しました。
最近はダイソーやセリアでも1つ100円で売ってるので、ためしにいくつか買ってみるのも良いかなと思います。
ガイドロープで転ぶ危険性もなくなりますし、サイトもおしゃれになりますし一石二鳥なアイテムです!!!
マット
最初はそれぞれ個別のマットを買ったのですが、子供1人に対して大人用マット1枚だと大きいし、2枚連結すると間が気になるし・・・ということで、ダブルサイズのマットを購入しました!!
今回購入したのは「コールマン(Coleman) エアーマット キャンパーインフレーターマットハイピーク ダブル」です
こちらですと厚さも10cmほどあり、ほぼベッドと同じような感覚で快適に寝ることが出来ます。
また子供2人と大人1人でダブルサイズのシェラフにくるまってちょうど良いサイズでもあります。
(妻が子供と寝るので私は過去に買ったシングルマットを使っています)
マットに直接寝ると汚れが気になったので丁度良い大きさのカバーをつけて使っています。
他にも最近は調理器具なども購入しているのですが、こちらはまた次回紹介させていただけたらと思います。
BigQuery 2021/11月のupdate情報まとめ
一気に寒くなって来ましたね。
歳のせいか、寒さに弱くなってきており、去年までよく毎日会社に通えていたな?と思っています。
リモートありがたい。
それでは先月までに引き続き11月のまとめもいってみましょう!
パラメータ化されたデータ型
すでにpreviewで出ていた機能がGAになりました
STRING/BYTES/NUMERIC/BIGNUMERIC型を宣言する際に桁数を指定出来るようになりました。
クレジットカードなど桁数が決まっている場合や、他のDBへのマイグレーション時には桁数を指定することで便利に使えそうです。
INFORMATION_SCHEMAでDDLが確認可能になりました
以下のDDLがINFORMATION_SCHEMAで確認可能になりました
INFORMATION_SCHEMA.ROUTINES
UDFとプロシージャのDDLINFORMATION_SCHEMA.SCHEMATA
DatasetのDDLINFORMATION_SCHEMA.TABLES
TableやviewなどのDDL
複数のスクリプトステートメントが追加されました
CASE search_expression:search_expressionで指定した値に対応するステートメントを実行


LABELS:labelで指定した場所に戻ることが出来る
BEGIN句/WHILE句/LOOP句/FOR句/REPEAT句で使用可能
REPEAT:UNTILで指定した条件を満たすまで繰り返す

FOR...IN:テーブルの各行について処理を実行する
以下の例の場合、select word...の結果で得た5行に対してLoopを行い各行に対してselectを行っている
結果として5行変えるのではなく、5回selectが行われる

承認済みDataset
承認済みviewのdataset版
承認済みdataset配下に作られたviewに対しては承認済みviewと同じように元テーブルに対するアクセス権がなくても参照可能に
11月のアップデートは以上となります。
BigQueryの話題ではないですがレビュワーとして少しだけ関わらせていただいた本が出版されました!
基盤自体の作り方から、データの整備の仕方、組織論まで網羅された本になりますので、よかったら読んでみてください

また来月!!
The Self-Service Data Roadmap について
この記事は、datatech-jp Advent Calendar 2021の7日目の記事となります。
The Self-Service Data Roadmapという本がとても評判良さそうで、読んでみたいけど英語版しかないので1人で読むのは厳しいなぁ・・・って思っていたところ、Twitterから発展してあれよあれよと輪読会が開催されることになりました。 amzn.to
輪読会は現在はdatatech-jpというコミュニティに発展をしています。
詳細は@syou6162さんがブログに書いてくださっているのでこちらを参考にしてください。
The Self-Service Data Roadmapの輪読会で私が担当した章は最初のIntroだったので、この本の全体感をここでは説明させてもらいます。
それぞの章の細かい内容は別の日のAdventCalendarでも触れてくれる方がいらっしゃる予定です。
The Self-Service Data Roadmapで述べられている内容は、タイトルの通り、Selfでデータを価値に変換出来るような基盤を作っていくにはどのようにしたら良いかが書かれています。
また、出てくるアーキテクチャの内容としては著者の関係もあるのか、Hadoopエコシステムに少し偏っていますが抽象化して考えればHadoop以外にも適用出来るものが多いです。
まず最初に3つの失敗するパターンが書かれています。
- データエンジニアとデータユーザの食い違い
- 新しい技術に飛びつく
- 全てに取り組む
データエンジニアの認識とデータユーザの認識齟齬とかどこの組織でもあるあるなのかなと思います。
このような失敗パターンがある上で、ではどのようにSelf-Service基盤を作っていけば良いかというと
まず全体を4つの工程に分けます

その上でさらに工程毎に細かく分けていきます

細かく分けることが出来たらそれぞれどれぐらい最終的にインサイトを出すために時間を掛かってるか見積もりします

もっとも時間のかかっている2~3メトリクスを特定/分析し、自動化までのロードマップを作成しましょう!!!
という流れです。
それぞれの time to XXX というメトリクスの詳細と改善方法はそれぞれ章毎に案内がされています。
なので全体を読まなくても例えばコンプライアンスに関して知りたい!でしたら、 time to comply の章だけを読むという読み方でも良さそうでした。
中には こんな夢のような基盤本当に世の中に実現するのか!? というような基盤の説明もありましたが、どこの章でも共通して書いてあったのは
銀の弾丸はない
でした。これを解決すればよい!というのはやはりなく、複合的に少しずつ解決していくのが遠回りなようでSelf-serviceへの近道なのかもしれません。
私が作成した資料はこちらですので興味ある方は是非とも読んでみてくださいmm
Advent Calendar 明日は@nana7dataさんです。よろしくお願いします!
BigQuery 2021/10月のupdate情報まとめ
Google Cloud Nextでわくわくする機能が発表されましたね!!!
発表内容は以下の動画にまとまっています
まだリリースされていない主な発表としては以下のようなものなどがあります。
- BQからCloudFunctionsを呼べるように

- SlotのAutoScaling

- テキスト検索インデックス

発表された機能も含めて、それでは先月までに引き続き10月のまとめもいってみましょう!
地理関数が追加
先月に引き続き地理関数の追加です
| 関数名 | 内容 |
|---|---|
| ST_BUFFER | Returns a GEOGRAPHY that represents the buffer around the input GEOGRAPHY. |
| ST_BUFFERWITHTOLERANCE | Returns a GEOGRAPHY that represents the buffer around the input GEOGRAPHY. |
BigQueryStorageAPIの料金体系が変更になりました
networkのegress料金など、一部料金が変更になりました。 詳しい価格はこちらから確認をお願いします。
他のDWHからのマイグレーションが可能に
BigQuery Migration Serviceとして、他のDWHからのMigrationがサポートされました!(現在対応のDWHはTeradataのみ)
データの移動はDataTransferServiceを使って行い、SQLの書き換えも行ってもらえるように!
SQLの書き換えはバッチモードとInteractiveモードがあり、InteractiveモードではBQコンソール上でSQLの変換が可能となりました。


StorageAPIがWriteにも対応
StorageAPIでWriteも出来るようになりました。
Readと同じように、より高スループットでの書き込みを行うことが出来ます。
Writeのモードは3つあります
Committed mode
書き込み後すぐに読み込みが可能。streaming処理向け
Pending mode
stream上にデータを貯めておき、commitのタイミングで書き込みが可能。comittされたタイミングですべてのデータが書き込みされる。 commitするまでデータは書き込まれないので、エラー時の再実行も可能。バッチ処理向け
Buffered mode
stream上のデータを任意のタイミングでflush出来る。
基本的にCommitted modeか Pending modeを使用すれば良いと思われるが、データの細かい制御をしたい場合向けだと思われる。
それぞれのサンプルコードはこちらを参照
料金もストリーミングinsertの50%ほどとお安くなっています。
AWSやAzureのデータをBigQueryで読み込み可能に
ついにBigQuery Omniがリリースされました!(しかもGA)
こちらは別途検証をしたいと思いますが、概要としてはS3のデータを指定してBigQueryからクエリが出来ます。
BigQueryのクラスタはAWSまたはAzure上に構築されますが、ユーザは管理を必要としません。
必要な権限をあたえ、コンソールからデータソースにS3を選べばS3のデータに対してBQからクエリをすることが出来ます!

検索結果をS3にexportすることも可能です
AzureのBlobStorageに対しても使用可能とdocにはなっているのですが、私の環境ではまだコンソールにAzureの選択肢は出てきませんでした。
現状、S3のリージョンや、データのjoinなど制限事項も色々あるようですので別途検証をしたいと思っています!
カラムレベルでの暗号化が可能に
CloudKMSを使用してカラムレベルでの暗号化が可能となりました。
暗号化したカラムを読み込む際はクエリ内で、複合関数の使用が必要です。
以前からカラムレベルの権限制御は出来ましたが、暗号化も可能となったことでセキュリティのオプションが増えたと思われます。
テーブルのスナップショット
6月のupdate情報まとめで紹介したテーブルスナップショットがGAとなりました!!
10月のアップデートは以上となります。
また来月!!
BigQuery 2021/9月のupdate情報まとめ
Google Cloud Nextが始まって続々とBQの新機能が発表されてますね! Nextで發表された内容のまとめは来月書きます
それでは先月までに引き続き9月のまとめもいってみましょう!
JOB履歴の削除が可能に
BQでは過去6ヶ月分のJOB履歴を持ちますが、JOB履歴の削除が可能になりました。(悪用しちゃだめですよ
bq rm -j ‘プロジェクト名:ロケーション.job_id’
where句に個人情報を入れてしまった場合などセンシティブデータを消したい場合に有効
メタデータ(INFORMATION_SCHEMAでの参照データなど)は消えますが、ログからは消えません
セッションが利用可能に
WebUIからセッションが使えるようになり、トランザクション(begin/commit/rollback)が利用可能に
本番作業を安心に出来るようになりました
変数や一時テーブルをセッション内で使いまわすことも可能
セッションを使うかはQuerySettingsから指定が出来ます
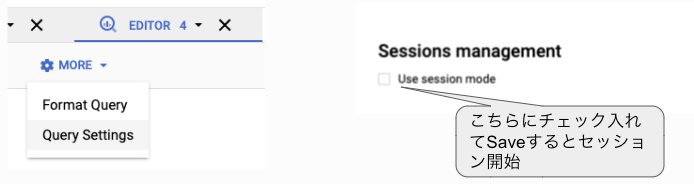
ブラウザのタブ毎に別のセッションを貼ることが可能
2つのセッションでDeadlockがかかるような処理を行った場合はupdateをしようとした時点でエラーが出ます
セッション中にエラーが起こってもrollbackやcommitはされません
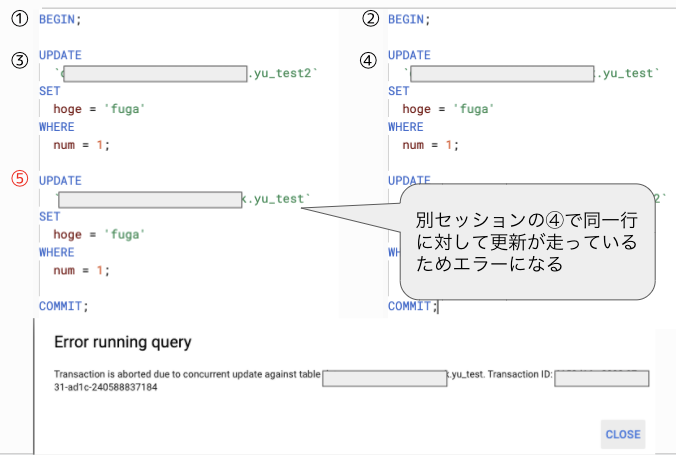
トランザクションレベルはSnapshot Isolationとなっており、トランザクションを開始した時点のスナップショットデータが読み込まれます。(ファジーリード/ファントムリードは起きない)
また、セッションは手動で終わらせることは出来ません。
24時間操作しないか、7日立つと自動的に終了し、commitしてない場合はrollbackされます。
多くの地理関数が利用可能に
以下の地理関数が利用可能になりました
| 関数名 | 内容 |
|---|---|
| ST_EXTERIORRING | Returns a linestring geography that corresponds to the outermost ring of a polygon geography. |
| ST_INTERIORRINGS | Returns an array of linestring geographies that corresponds to the interior rings of a polygon geography. |
| ST_ANGLE | Returns the angle between two intersecting lines. |
| ST_AZIMUTH | Returns the azimuth of a line segment formed by two points. |
| ST_NUMGEOMETRIES | Returns the number of geometries in a geography. |
| ST_GEOMETRYTYPE | Returns the Open Geospatial Consortium (OGC) geometry type that describes a geography as a string. |
| ST_BOUNDINGBOX | Returns a STRUCT that represents the bounding box for a geography. |
| ST_EXTENT | Returns a STRUCT that represents the bounding box for a set of geographies. |
| S2_COVERINGCELLIDS | Returns an array of S2 cell IDs that cover a geography. |
| S2_CELLIDFROMPOINT | Returns the S2 cell ID covering a point geography. |
クエリ結果のダウンロード上限が変更
クエリの結果をローカルにダウンロードする際の上限が10MBになりました。
(今までは16,000行 or 10MBだったと思う)
加えてnestedカラムや配列カラムもCSVにダウンロード可能になりました。
(ダウンロードするとカラムの中身はJSONでJSONのCSVとなってます)
承認済みTable関数
承認済みviewのTable関数版です
関数内で参照しているテーブルに対しての閲覧権限がなくても関数の権限があればデータの参照が可能
9月のアップデートは以上となります。
GoogleCloudNext前だからか、少なかったですね。また来月!!
BigQuery 2021/8月のupdate情報まとめ
先月までに引き続き8月のまとめもいってみましょう!
ODBC/JDBC driverのバージョンアップ
エンハンス、bugfixなどが含まれています。
CREATE TABLE LIKE
既存のテーブルからスキーマ情報をコピーしてテーブルを作成します
(データのコピーはされない)
カラムのdescriptionなど、メタデータのコピーもされます
{CREATE TABLE | CREATE TABLE IF NOT EXISTS | CREATE OR REPLACE TABLE}
[[project_name.]dataset_name.]table_name
LIKE [[project_name.]dataset_name.]source_table_name
[PARTITION BY partition_expression]
[CLUSTER BY clustering_column_list]
[OPTIONS(table_option_list)]
[AS query_statement]
CREATE TABLE COPY
既存のテーブルと同じスキーマ、データを持つテーブルを作成します
メタデータのコピーもされます
{CREATE TABLE | CREATE TABLE IF NOT EXISTS | CREATE OR REPLACE TABLE}
[[project_name.]dataset_name.]table_name
COPY [[project_name.]dataset_name.]source_table_name
[OPTIONS(table_option_list)]
カラムの型変更が可能に
ALTER COLUMN SET DATA TYPEを使って、カラムの型変更が可能になりました
どの型にでも変更出来るわけではなく、INT64からBIGNUMERICなどより制約のゆるい型への変更のみ可能です
INT64からSTRINGの型変換も出来ませんでした
注意書きとして、型を変更するテーブルがマテリアライズドビューから参照されている場合は、マテリアライズドビューに対するクエリがエラーとなってしまうと書かれています
この問題を回避するには一度マテリアライズドビューを削除し作り直す必要があります
ALTER TABLE [IF EXISTS] [[project_name.]dataset_name.]table_name ALTER COLUMN [IF EXISTS] column_name SET DATA TYPE data_type
Spannerへの外部クエリが可能になりました
EXTERNAL_QUERY関数を使用して、BQからSpannerへのクエリが可能になりました
BQに対応していない型がある場合はクエリが失敗します
BQが単一リージョンだった場合は同じリージョンにあるSpannerにのみクエリが可能
また、spannerへのクエリは読み取り専用です
BQから直接クエリ出来るサービスとしては他に
- GCS
- CloudSQL
- スプレッドシートなどがあります
SELECT c.customer_id, c.name, rq.first_order_date FROM mydataset.customers AS c LEFT OUTER JOIN EXTERNAL_QUERY( 'my-project.us.example-db', '''SELECT customer_id, MIN(order_date) AS first_order_date FROM orders GROUP BY customer_id''') AS rq ON rq.customer_id = c.customer_id GROUP BY c.customer_id, c.name, rq.first_order_date;
BigQuery 管理リソースグラフが使用可能に
previewだったものがGAになりました
管理リソースグラフはreservations(定額制のBQ)を使っている場合のみ使用出来ます
組織全体 > reservation > プロジェクト > ユーザー > job と深堀してどこでどれだけslotが使われているか確認することが出来ます
スロットの容量見積もりツールが使用可能に
reservationsを使う時に一体どれだけslotを買えばいいのかは見積もりが非常に辛いです
こちらのツールでは現在指定しているslot数に対してどれほどのslotを使っているかが可視化されます

こちらでも見積もり方法をのせているブログがあるので良かったら参考にしてみてください
Parquetフォーマットでのエクスポートが可能に
previewだったものがGAになりました
Parquet形式でのエクスポートが出来るようになりました
コンソールからのエクスポートでもParquetが指定可能です
BQで選べるファイルのフォーマット * テキストフォーマット(例:CSV、JSON) * 行指向フォーマット(例:AVRO) * 列指向(カラムナ)フォーマット(例:Parquet)

8月のアップデートは以上となります。
夏休みの影響(?)なのか、少なかったですね。また来月!!
BigQuery 2021/7月のupdate情報まとめ
6月のまとめに引き続き7月のまとめもいってみましょう!
ODBC/JDBC driverのバージョンアップ
6月に発表された型に桁数を持たせられる機能の他bugfixなどが含まれています。
マテリアライズドビューが集約無しクエリに対応
今まではSUMやAVGなどの集約関数を使ったクエリでしかマテビューが作れなかったが、集約関数を使わなくてもマテビューが作成可能になりました。
クラスタ化や、フィルタリングの検証に使えます。
クラスタ化されたマテビューは、indexのように機能し、元テーブルに対してのクエリもマテビューからのデータを参照するようになります。
BigQueryではoracleのクエリリライトと同じような機能があり、a というテーブルを元に、 mv_a というマテビューを作った場合、 a に対するクエリでも mv_a を見たほうがクエリコストが低いとクエリオプティマイザが判断した場合、内部的に mv_a を参照される場合があります。
BigQuery は、事前に計算されたマテリアライズド ビューの結果を利用し、可能な場合にはベーステーブルからの差分のみを読み取って最新の結果を計算します。マテリアライズド ビューに直接クエリを発行できるのはもちろん、ベーステーブルに対するクエリを処理するために BigQuery オプティマイザーでマテリアライズド ビューを使用することもできます。
公式docでは以下のような例が記載されています
データの再クラスタ化
ベーステーブルと異なるクラスタリング スキームを使用したクエリの多くを発行する場合、マテリアライズド ビューを使用するとクエリのパフォーマンスが向上する可能性があります。
CREATE MATERIALIZED VIEW dataset.mv CLUSTER BY y AS SELECT * FROM dataset.base_table;
データの事前フィルタリング
テーブルの特定のサブセットのみを読み取るクエリを頻繁に実行する場合は、マテリアライズド ビューを使用してクエリのパフォーマンスを向上させることができます。
CREATE MATERIALIZED VIEW dataset.mv CLUSTER BY x AS SELECT * FROM dataset.base_table WHERE y < 1000;
データの事前計算
コンピューティング コストが高い関数を頻繁に使用する場合や、大きな列から少量のデータを抽出する場合は、マテリアライズド ビューを使用するとクエリのパフォーマンスが向上します。
CREATE MATERIALIZED VIEW dataset.mv AS SELECT x, JSON_EXTRACT(string_field, "$.subfield1.subfield2") subfield2 FROM dataset.base_table;
発行したクエリがマテビューを参照したかどうかはクエリプランのデータスキャン量などを見ると確認することが出来ます。
マテリアライズドビューが内部結合クエリに対応
今までは結合を使えなかったが、内部結合(inner join)を使ったクエリでもマテビューが作成可能になりました。
クロス結合、完全結合、左結合、右結合は非対応
ファクトテーブルとディメンションテーブルのように、頻繁にjoinされるテーブルのクエリはマテビューを作っておくことでパフォーマンス改善が可能に
(テーブルの参照順はviewとクエリで同一でなければいけない)
CONTAINS_SUBSTR関数
式(文字列や数値、配列など)に値(stirngで指定)が存在するかどうかを確認出来ます。(正規化して比較)
式が文字列の場合大文字小文字の区別をしません。
CONTAINS_SUBSTR関数はWhere句での条件にも指定ができ、テーブル全体から特定の文字列が入っている行を検索など全文検索ぽいことも出来る非常に便利な関数です。
使用例
■戻り値がTrueとなるパターン SELECT CONTAINS_SUBSTR('the blue house', 'Blue house') AS result; SELECT CONTAINS_SUBSTR((23, 35, 41), '35') AS result; -- '\u2168'は正規化するとⅨのため trueとなる SELECT CONTAINS_SUBSTR('\u2168', 'IX') AS result; ■Where句でも使用可能 -- Recipes テーブルのすべての列から値 toast を検索し、この値を含む行を返します。 SELECT * FROM Recipes WHERE CONTAINS_SUBSTR(Recipes, 'toast'); -- Recipe テーブルの Lunch 列と Dinner 列で値 potato を検索し、いずれかの列にこの値が含まれている場合にその行を返します。 SELECT * FROM Recipes WHERE CONTAINS_SUBSTR((Lunch, Dinner), 'potato');
PIVOT関数
エクセルのピボットテーブルと同じような操作が関数で可能に。
(以前もPreviewで使用出来ましたが7月にGAになりました。)
SQLからreservations(slot)の管理が可能に
slotの購入、reservationの作成、reservationへのアサインなどreservationsに関する操作がSQLで実行可能になりました。
スケジュールドクエリと組み合わせることで、特定の時間のみslotを増やすなどの設定が容易に行えます。
-- slotの購入 CREATE CAPACITY -- reservationsの作成 CREATE RESERVATION -- reservationsへのアサイン CREATE ASSIGNMENT -- slotの開放 DROP CAPACITY -- reservationsの削除 DROP RESERVATION -- アサインからdrop DROP ASSIGNMENT
6月には権限設定がSQLから出来るようになったりと、BQではAPIだけではなくSQLからも実行出来ることが増えて来てますね。
INFORMATION_SCHEMAでDMLの結果が取得可能に
INFORMATION_SCHEMA.JOBS_BY_(PROJECT / USER)にdml_statisticsカラムが追加
・INSERT and MERGEによって追加された行数
(loadは含まない)
・UPDATE and MERGEによって更新された行数
・DELETE, MERGE and TRUNCATEによって削除された行数
が確認出来ます
例
SELECT SUM(dml_statistics.inserted_row_count), SUM(dml_statistics.updated_row_count), SUM(dml_statistics.deleted_row_count), FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 8 DAY) AND TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) AND job_type = "QUERY" AND statement_type != "SCRIPT";
INTERVAL型
時間間隔を保持出来るINTERVAL型を使えるようになりました。
(フォーマット:Y-M D H:M:S[.F])
使用例
CREATE TABLE yu_work.interval_test1 ( aa INTERVAL); -- データ登録例 INSERT INTO yu_work.interval_test1 VALUES (INTERVAL 1 DAY); INSERT INTO yu_work.interval_test1 VALUES (CAST('2-4 26 22:00:00' AS INTERVAL)); SELECT * FROM yu_work.interval_test1 ;

INTERVAL型の使い所について考察しているブログもありました!
【BigQuery】2021.7.27にPreview公開されたINTERVAL型を試してみる - とりゅふの森
7月のアップデートは以上となります。
INFORMATION_SCHEMAはどんどん便利になっていきますね。今後load数や、データ量なども取れるようになっていくといいな〜と思っています。